
About Me
🔥 News
-
2025.7: 🎉🎉 SPOT is accepted by IEEE T-PAMI 2025.
-
2025.6: 🎉🎉 Two papers (Lumina Image 2.0 and Chimera) are accepted by ICCV 2025. One is about text-to-image generation, the other is about multimodal reasoning.
-
2025.5: 🎉🎉 Two papers (SurveyForge and Dolphin) are accepted by ACL 2025. Both are introduced for accelerate scientific research.
-
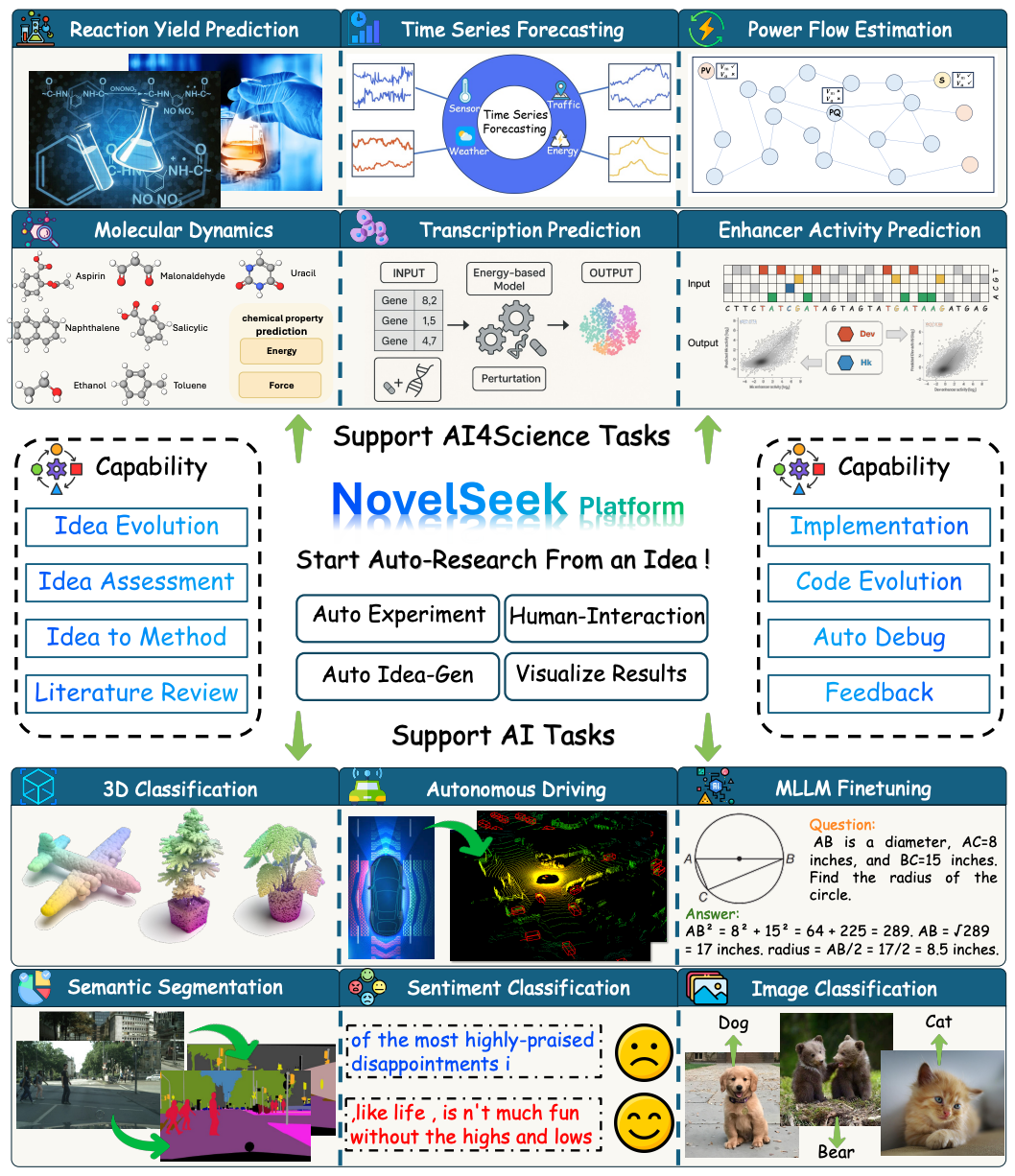
2025.5: 🎉🎉 We release NovelSeek, a unified closed-loop multi-agent framework for Automatic Scientific Research.
-
2025.2: 🎉🎉 One paper (CST-Stereo) is accepted by CVPR 2025. CST-Stereo introduce a unified self-training framework for iterative-based stereo matching models.
-
2024.12: 🎉🎉 One paper (GeoX) is accepted by ICLR 2025. GeoX reveals the large potential of formalized visual-language pre-training in enhancing geometric problem-solving abilities.
-
2024.12: 🎉🎉 One paper (AIOStereo) is accepted by AAAI 2025. AIOStereo can transfer knowledge from multiple vision foundation models into a single stereo matching model flexibly.
-
2024.10: 🎉🎉 I recieve the national scholarship.
-
2024.09: 🎉🎉 Two papers (AdaptiveDiffusion and 3DET-Mamba) are accepted by NeurIPS 2024. One is about training-free acceleration of diffusion model, another is about mamba architecture in 3D detection.
-
2024.07: 🎉🎉 One paper (Reg-TTA3D) is accepted by ECCV 2024. We explore test-time adaptive 3d object detection for the first time.
-
2024.01: 🎉🎉 One paper (ReSimAD) is accepted by ICLR 2024. We propose a zero-shot generalization framework by reconstructing mesh and simulating target point clouds.
-
2023.09: 🎉🎉 One Paper (AD-PT) is accepted by NeurIPS 2023.We explore 3D pre-training pipeline to obtain backbones with strong generalization capability.
-
2023.02: 🎉🎉 Two Papers (Bi3D and Uni3D) are accepted by CVPR 2023. One is about active domain adaptation for 3D object detection, another is about multi-dataset training for 3d object detection.
-
2022.07: 🎉🎉 One Paper (HelixFormer) is accepted by ACM'MM 2022. We explore Transformer architecture on few-shot fine-grained classification task.
📝 Publications & Preprints
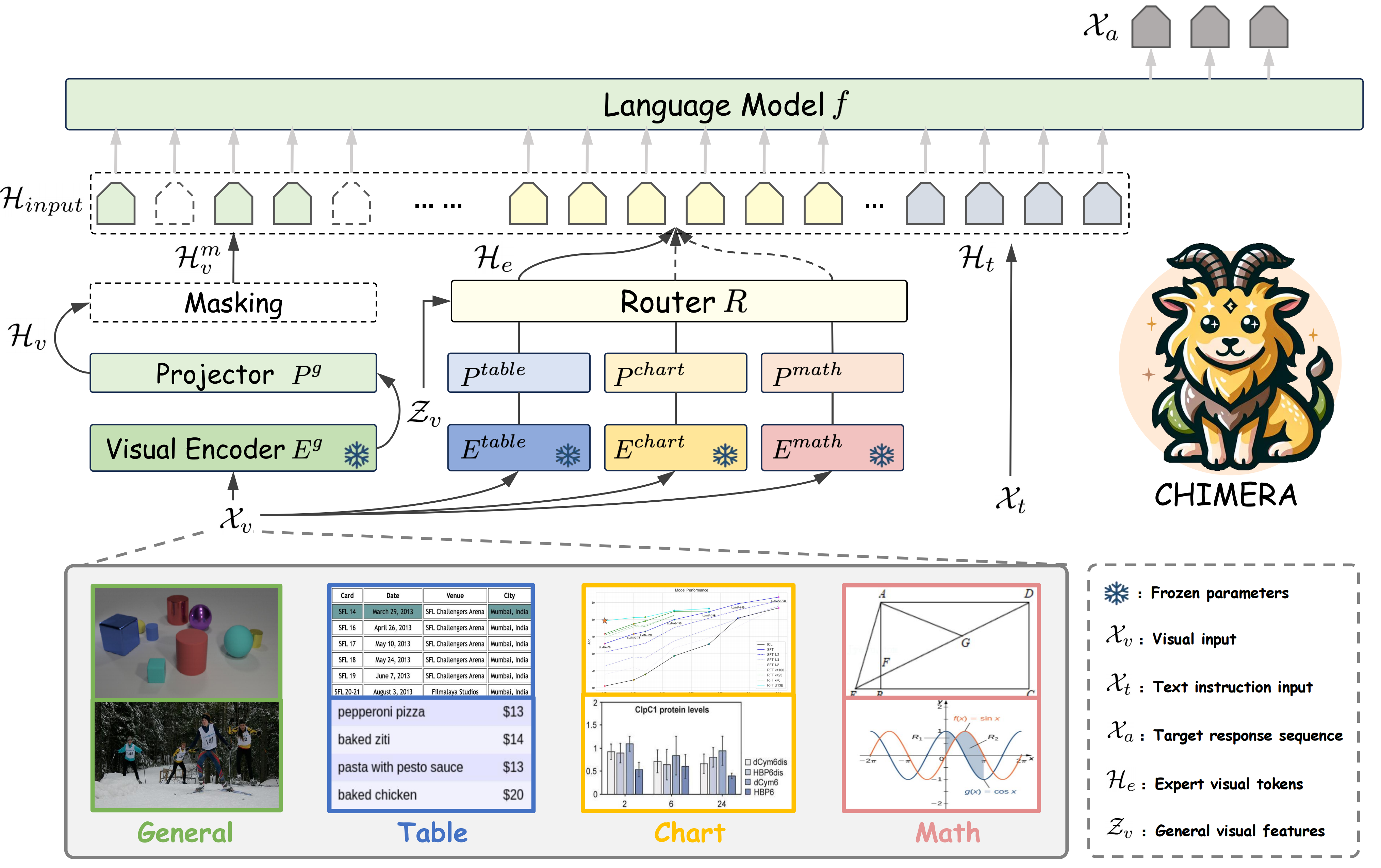
Chimera: Improving Generalist Model with Domain-Specific Experts
Tianshuo Peng*, Mingsheng Li*, Jiakang Yuan, Hongbin Zhou, Renqiu Xia, Renrui Zhang, Lei Bai, Song Mao, Bin Wang, Aojun Zhou, Botian Shi, Tao Chen, Bo Zhang, Xiangyu Yue
- a scalable and low-cost multi-modal pipeline designed to boost the ability of existing LMMs with domain-specific experts.

Lumina-Image 2.0: A Unified and Efficient Image Generative Framework
Qi Qin, Le Zhuo, Yi Xin, Ruoyi Du, Zhen Li, Bin Fu, Yiting Lu, Jiakang Yuan, Xinyue Li, Dongyang Liu, Xiangyang Zhu, Manyuan Zhang, Will Beddow, Erwann Millon, Victor Perez, Wenhai Wang, Conghui He, Bo Zhang, Xiaohong Liu, Hongsheng Li, Yu Qiao, Chang Xu, Peng Gao
- State-of-the-art text-to-image generation model.
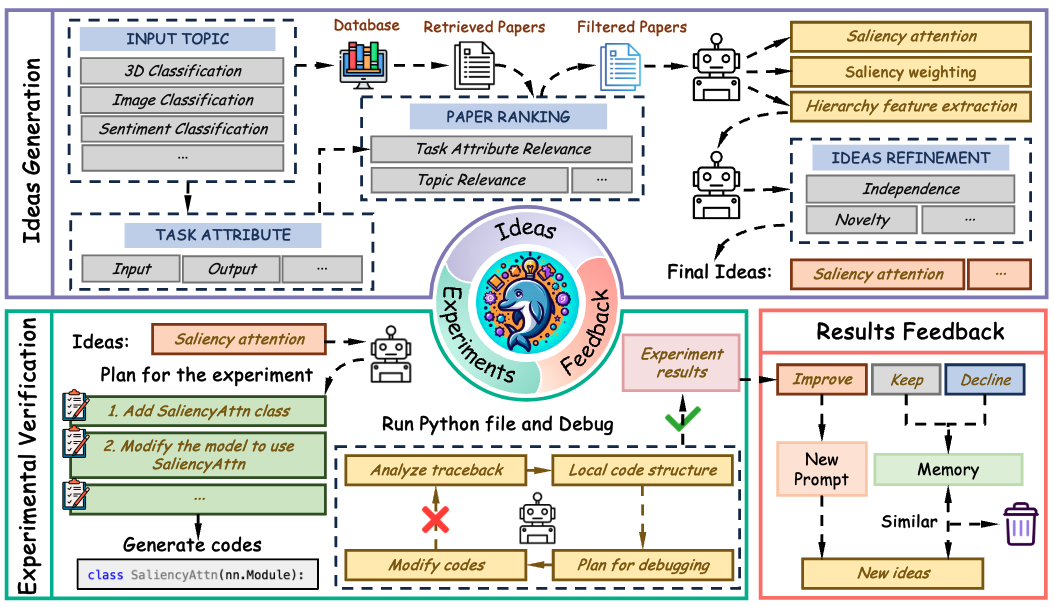
Dolphin: Moving Towards Closed-loop Auto-research through Thinking, Practice, and Feedback
Jiakang Yuan, Xiangchao Yan, Shiyang Feng, Bo Zhang, Tao Chen, Botian Shi, Wanli Ouyang, Yu Qiao, Lei Bai, Bowen Zhou
- Propose Dolphin, a closed-loop auto-research framework.
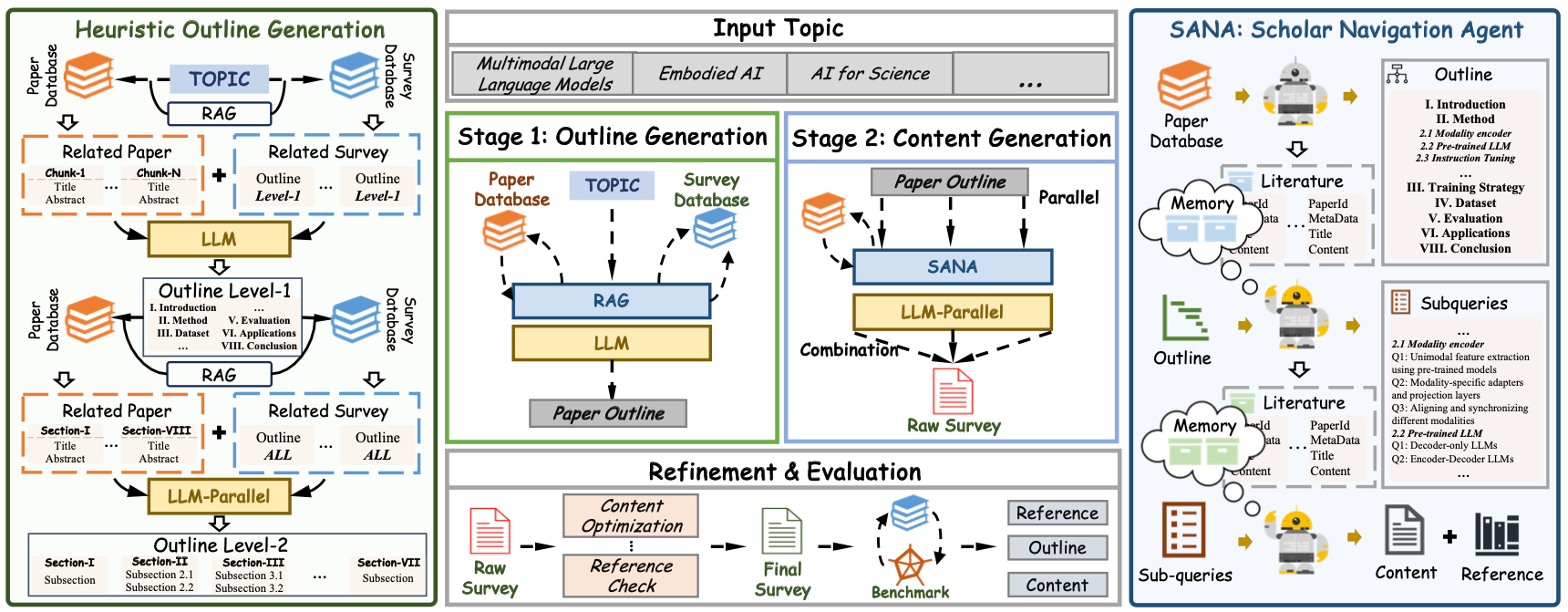
Xiangchao Yan*, Shiyang Feng*, Jiakang Yuan, Renqiu Xia, Bin Wang, Bo Zhang, Lei Bai
- Propose SurveyForge which can automatically generate and refine the content of survey.
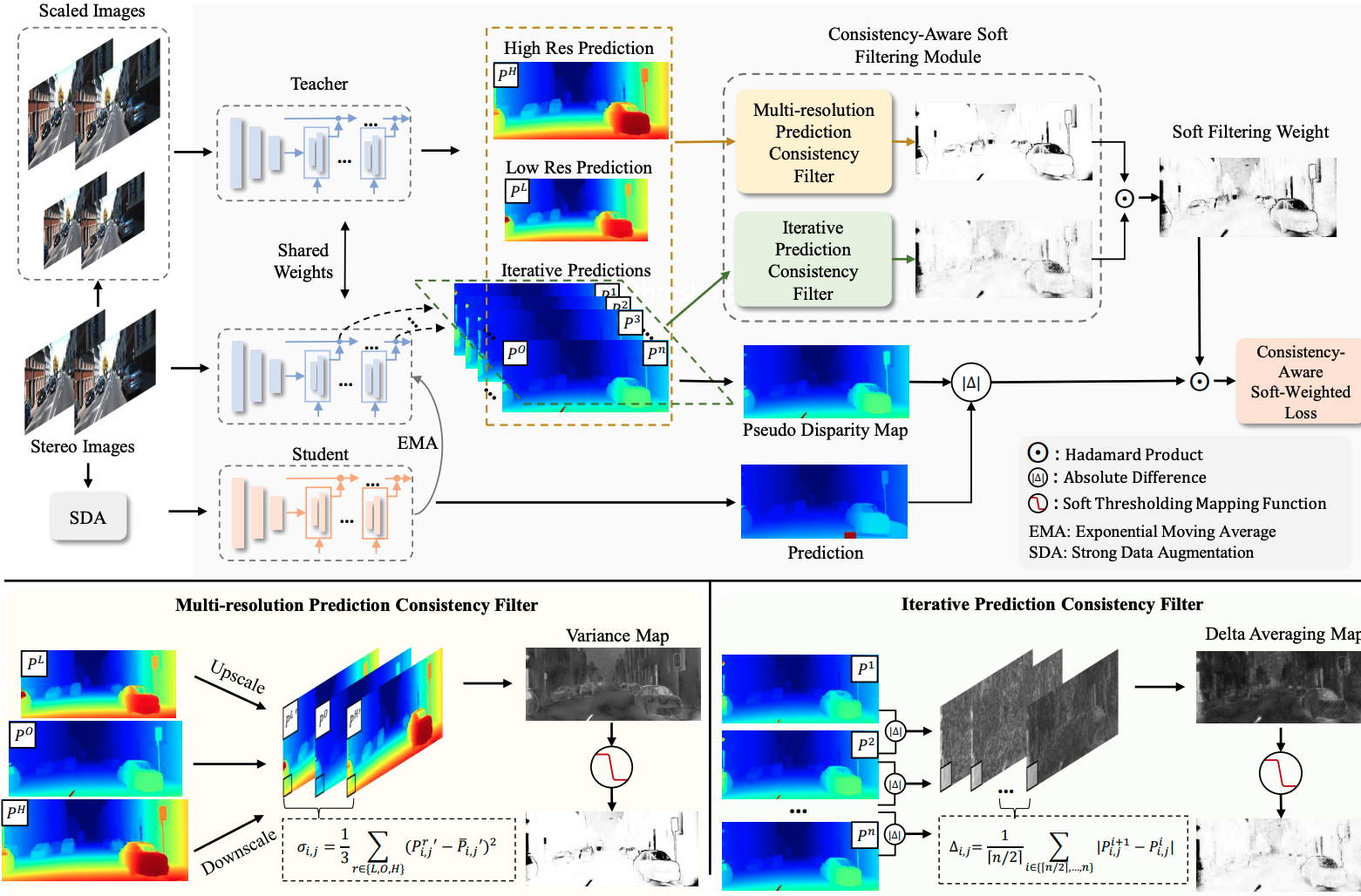
Consistency-aware Self-Training for Iterative-based Stereo Matching
Jingyi Zhou*, Peng Ye*, Haoyu Zhang, Jiakang Yuan (Project Leader), Qiang Rao, YangChenXu Liu, Cailin Wu, Feng Xu, Tao Chen
- Propose CST-Stereo, which achieves impressive results in various scenarios, including in domain, domain adaptive and domain generalization,
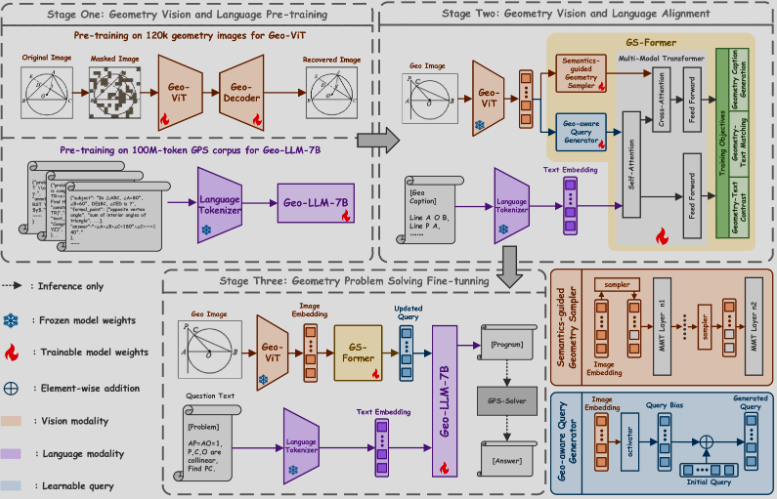
GeoX: Geometric Problem Solving Through Unified Formalized Vision-Language Pre-training
Renqiu Xia*, Mingsheng Li*, Hancheng Ye, Wenjie Wu, Hongbin Zhou, Jiakang Yuan, Tianshuo Peng, Xinyu Cai, Xiangchao Yan, Bin Wang, Conghui He, Botian Shi, Tao Chen, Junchi Yan, Bo Zhang
- Propose GeoX, a multi-modal large model focusing on geometric understanding and reasoning tasks which reveals the large potential of formalized visual-language pre-training in enhancing geometric problem-solving abilities.
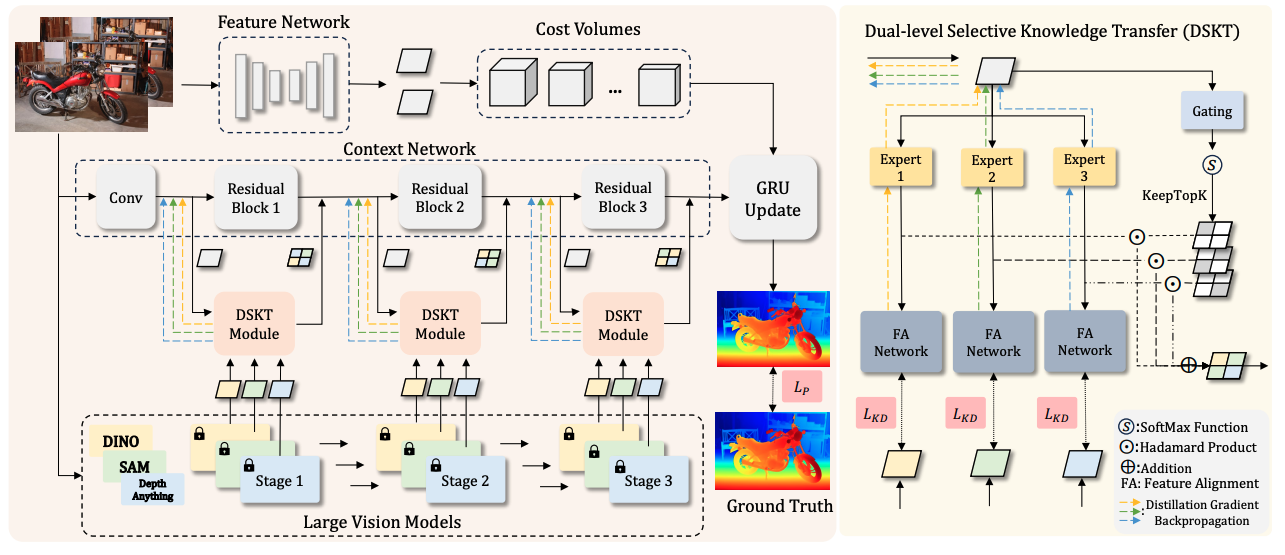
All-in-One: Transferring Vision Foundation Models into Stereo Matching
Jingyi Zhou*, Haoyu Zhang*, Jiakang Yuan*, Peng Ye, Tao Chen, Hao Jiang, Meiya Chen, Yangyang Zhang
- Propose AIOStereo to flexibly select and transfer knowledge from multiple heterogeneous VFMs to a single stereo matching model. (Rank 1st on Middlebury Stereo Evaluation)
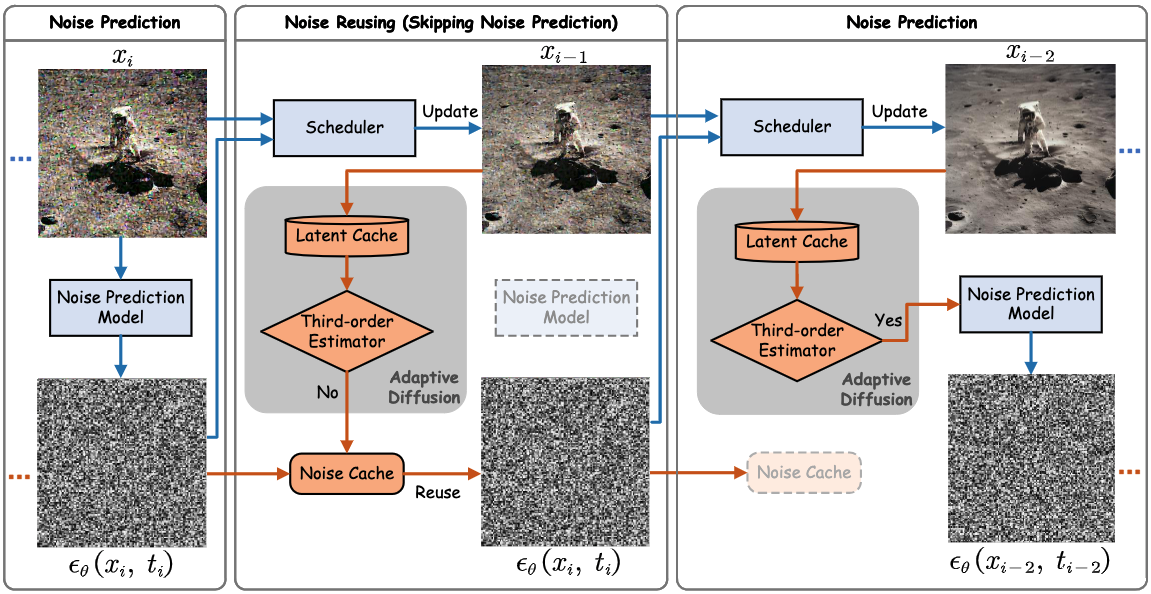
Training-Free Adaptive Diffusion with Bounded Difference Approximation Strategy
Hancheng Ye*, Jiakang Yuan*, Renqiu Xia, Xiangchao Yan, Tao Chen, Junchi Yan, Botian Shi, Bo Zhang
- Propose AdaptiveDiffusion to adaptively reduce the noise prediction steps during the denoising proces guided by the third-order latent difference.
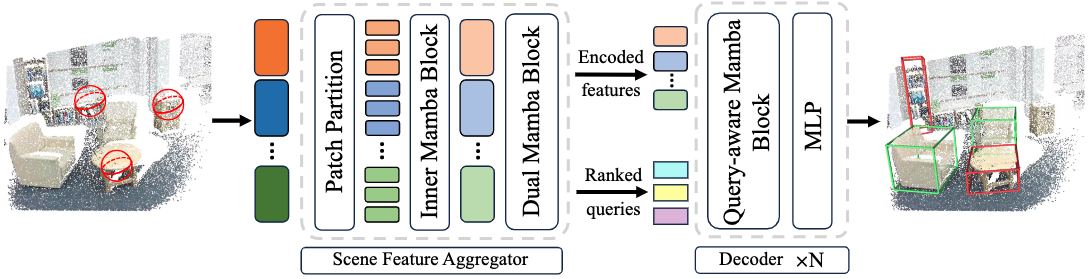
3DET-Mamba: State Space Model for End-to-End 3D Object Detection
Mingsheng Li*, Jiakang Yuan*, Sijin Chen, Lin Zhang, Anyu Zhu, Xin Chen, Tao Chen
- Exploit the potential of Mamba architecture on 3D scene-level perception for the first time.
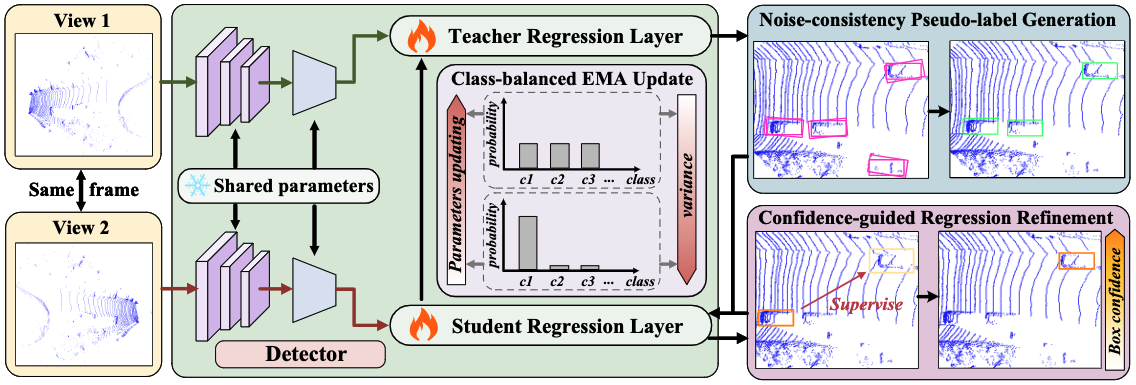
Reg-TTA3D: Better Regression Makes Better Test-time Adaptive 3D Object Detection
Jiakang Yuan, Bo Zhang, Kaixiong Gong, Xiangyu Yue, Botian Shi, Yu Qiao, Tao Chen
- Explore a new task named test-time domain adaptive 3D object detection and propose a pseudo-label-based test-time adaptative 3D object detection method.
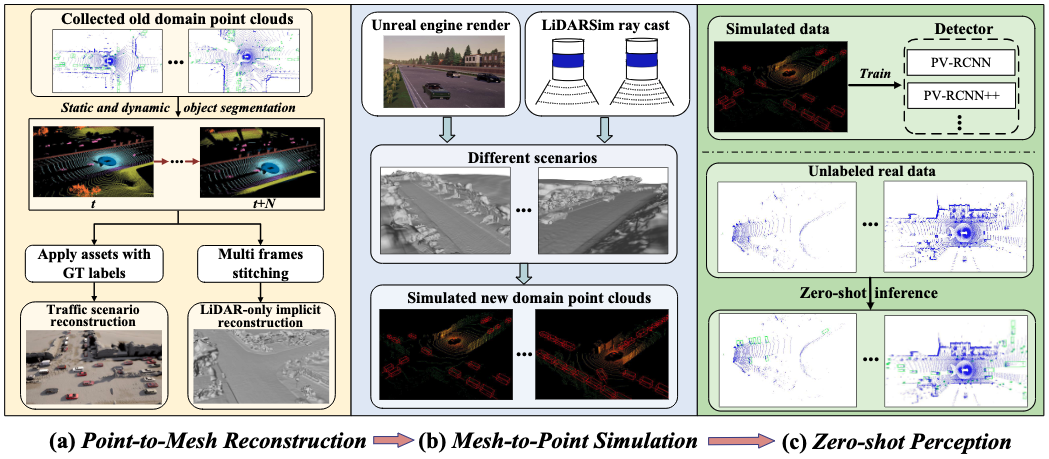
Bo Zhang*, Xinyu Cai*, Jiakang Yuan, Donglin Yang, Jianfei Guo, Xiangchao Yan, Renqiu Xia, Botian Shi, Min Dou, Tao Chen, Si Liu, Junchi Yan, Yu Qiao
- Provide a new perspective and approach of alleviating the domain shifts, by proposing a Reconstruction-Simulation-Perception scheme.
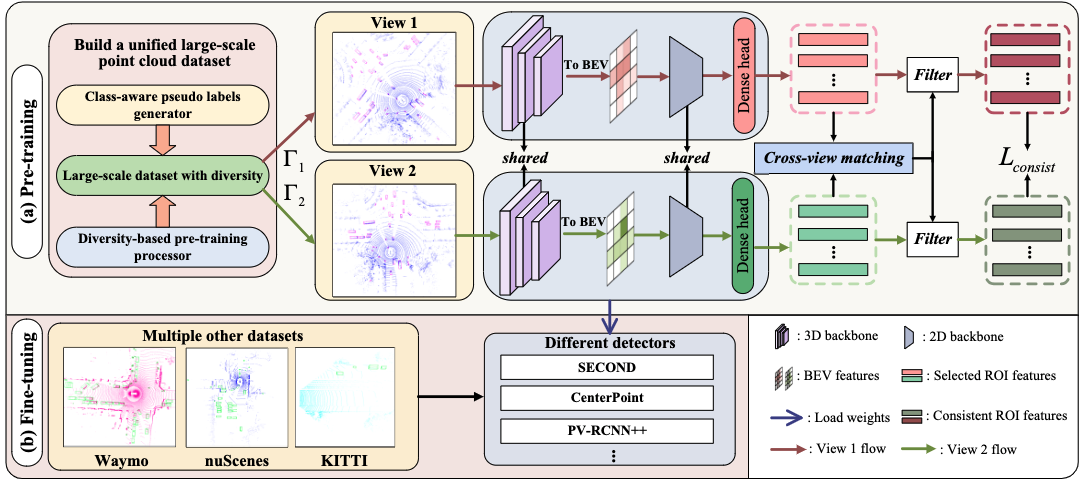
AD-PT: Autonomous Driving Pre-Training with Large-scale Point Cloud Dataset
Jiakang Yuan, Bo Zhang, Xiangchao Yan, Tao Chen, Botian Shi, Yikang Li, Yu Qiao
- Build a large-scale pre-training point-cloud dataset with diverse data distribution, and meanwhile learn generalizable representations.
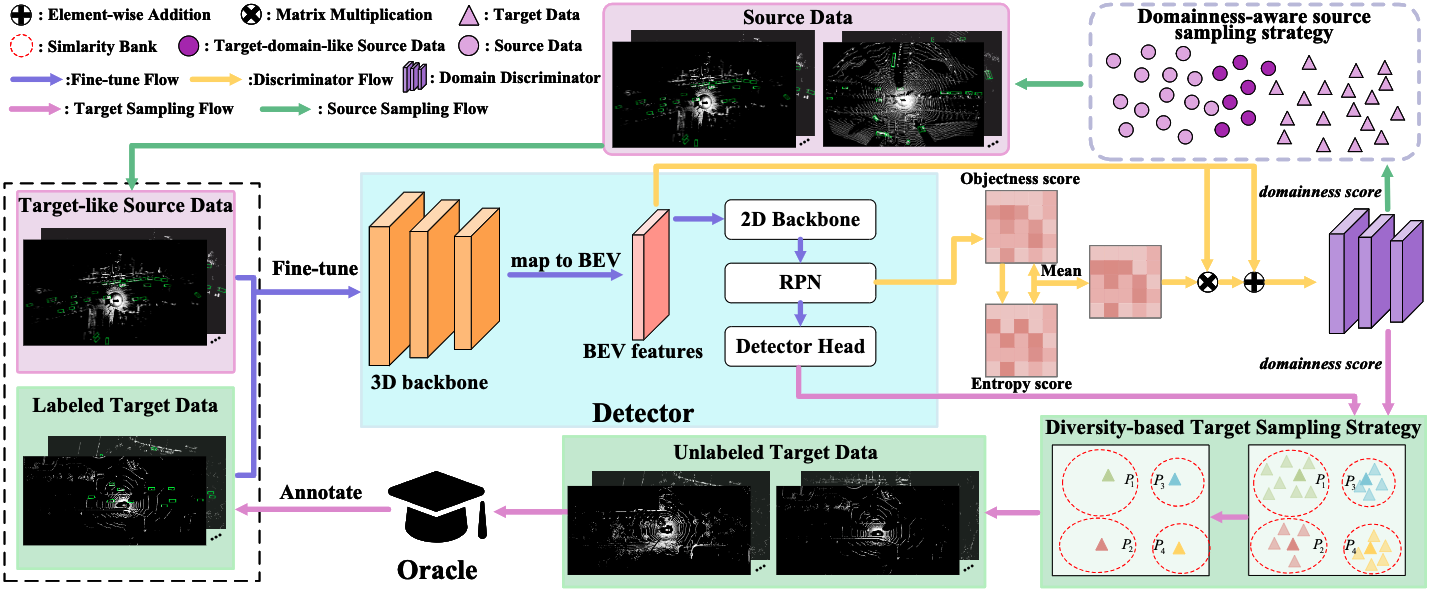
Bi3D: Bi-domain Active Learning for Cross-domain 3D Object Detection
Jiakang Yuan, Bo Zhang, Xiangchao Yan, Tao Chen, Botian Shi, Yikang Li, Yu Qiao
- Propose a Bi-domain active learning approach which select samples from both source and target domain to solve the cross-domain 3D object detection task.
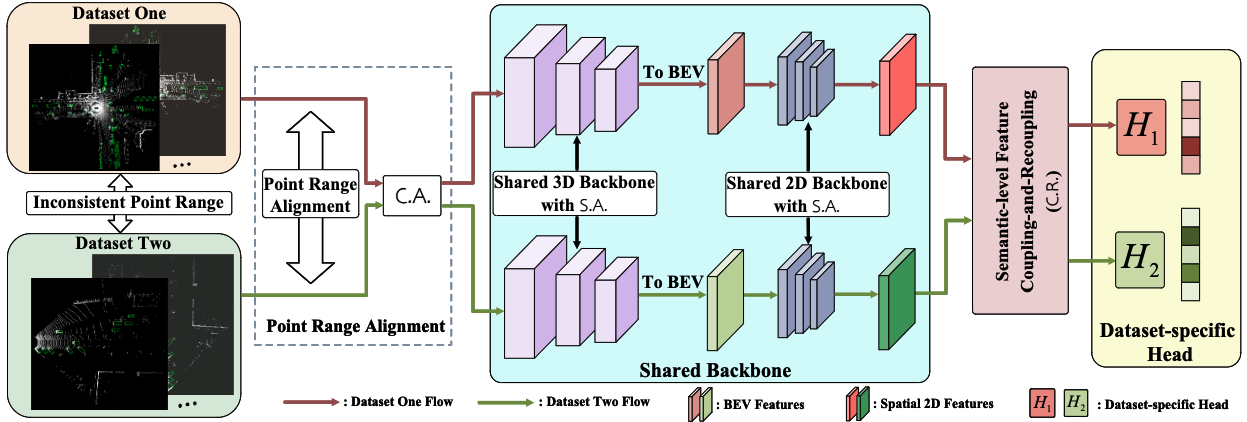
Uni3D: A Unified Baseline for Multi-dataset 3D Object Detection
Bo Zhang, Jiakang Yuan, Botian Shi, Tao Chen, Yikang Li, Yu Qiao
- Present a Uni3D which tackle multi-dataset 3D object detection from data-level and semantic-level.
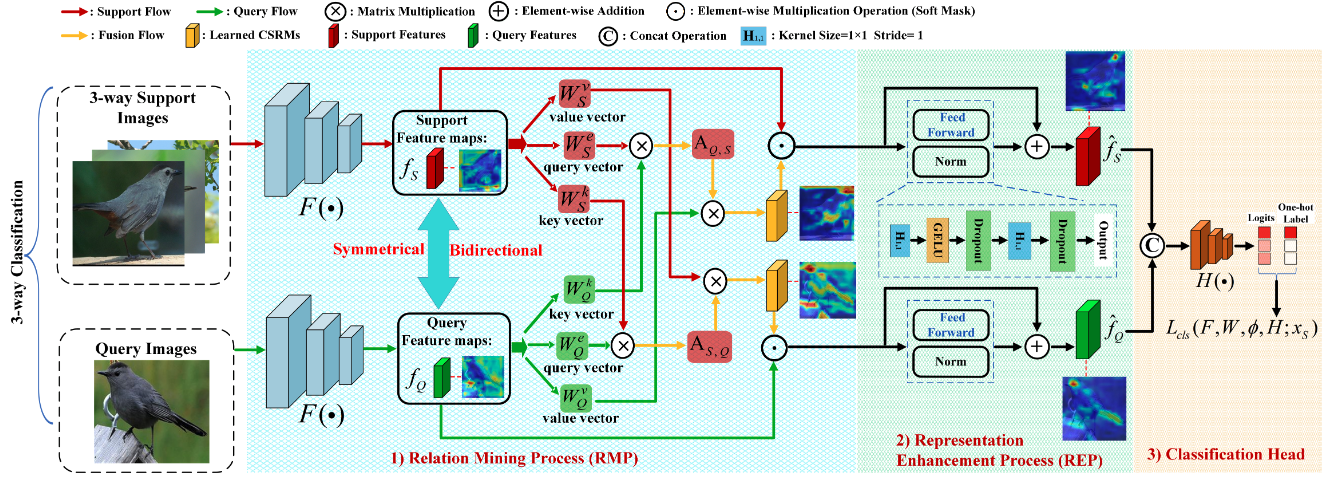
Bo Zhang*, Jiakang Yuan*, Baopu Li, Tao Chen, Jiayuan Fan, Botian Shi
- Propose a Transformer-based double-helix model to achieve the cross-image object semantic relation mining in a bidirectional and symmetrical manner.
📖 Educations
- 2022.09 - Now, Ph.D. Candidate, School of Information Science and Technology, Fudan University.
- 2018.06 - 2022.06, Bachelor Degree, School of Information Science and Technology, Fudan University.
💬 Invited Talks
- 2023.09, Invited talk of Effcient Pre-training of Autonomous Driving. [Video]
- 2023.07, Invited talk of Towards 3D General Representation at Techbeat. [Video]
- 2023.03, Invited talk of Transferable of Autonomous Driving. [Video]
💻 Internships
- 2024.10 - Now, Shanghai AI Laboratory, China.
- 2022.08 - 2024.02, Shanghai AI Laboratory, China.
📝 Academic Services
- Reviewer of CVPR, ICCV, ECCV, NeurIPS, ICML, ICLR, T-IP, T-CSVT, T-MM.